We might for instance have a suprogram like this (in C):
h()
{
...
return;
}
and then two or more different callers like this:
f()
{
h();
}
...
g()
{
h();
}
While we can implement the call to the subprogram using a JAL
instruction, the problem is with the return address. The subprogram
cannot simply execute a JAL instruction at the end, since it does not
know whether to jump to a place inside the function f or
a place inside the function g.Early versions of implementations of the Fortran programming language solved the problem by storing the return address in the memory cell immediately preceding the subprogram itself, and using an instruction JIN (jump indirect) to return to the caller. The JIN instruction is similar to the JAL instruction in that it jumps unconditionally. But whereas the argument of the JAL instruction is the address to jump to, the argument of the JIN instruction is the address of a memory cell containing the address to jump to.
With such an instruction, we can implement the subprogram above like this:
h-1: 0
h: ...
jin h-1
Here, we have two addresses, symbolically indicated as
h-1 and h respectively. The address
h-1 is simply h minus one, so both are
known at compile time. The address h-1 is used to store
the return address, whereas the address h is the entry
point of the subprogram. Notice that when the subprogram has finished
its computation, it jumps indirectly to the address stored in the cell
whose address is h-1. We can now implement our callers
like this:
f: ...
ldimm fhret
copy
st h-1
...
jal h
fhret: ...
...
f: ...
ldimm ghret
copy
st h-1
...
jal h
ghret: ...
Here, we have introduced in each caller, an address to return to after
the subprogram has finished (fhret and ghret). As you can see, we use
this address as argument to an LDIMM instruction. We then store the
address in the cell reserved for the return address in the callee (the
subprogram). Finally, we jump unconditionally (JAL instruction) to
the entry point of the subprogram.We know have a rudimentary subprogram call protocol, i.e., a set of rules that determines exactly the responsibilities of a caller and a callee in order for subprograms to work.
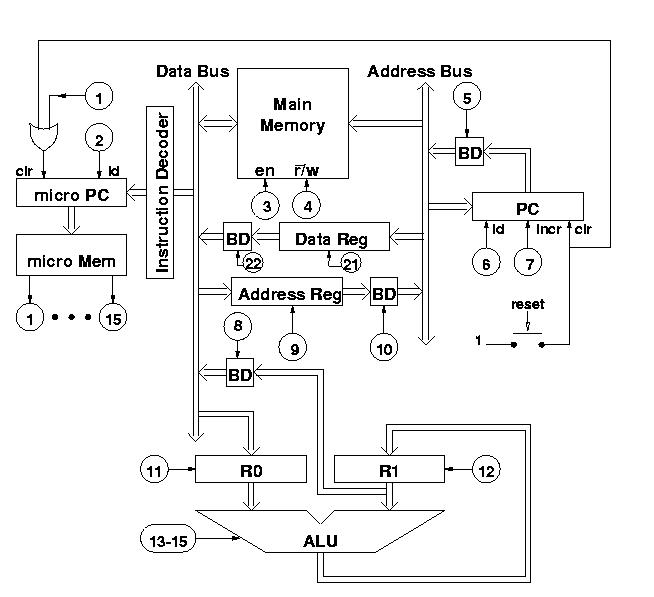
Our call protocol depends on the existance of a JIN instruction, which we don't have. This instruction can, however, be implemented without further modifications to the existing architecture. The plan for its implementation is as follows: First use MOPs 5, 3, and 9 to address main memory and store the argument of the instruction in the address register. Also increment PC. Then, in the next cycle, use the contents of the address register to address memory (MOPS 10 and 3) to obtain the address to jump to and store it in the address register (MOP 9 again). Then in the final cycle, store the contents of the address register into PC (MOPs 10 and 6). Here is the complete micro program:
......: 00101010100000000000 (JIN) ......: 00100000110000000000 (JIN) ......: 10000100010000000000 (JIN)We have omitted the exact addresses in the micro memory as well as the instruction code, since these are determined as usual by the first ones available.
There is a major inconvenience with this solution to subroutine calling, however. The caller must use the registers in order to load and store the return address. We can do better than that if we have a special instruction for subprogram calling. Most architectures contain such an instruction that is usually called JSR (jump to subroutine). The JSR instruction takes care of both storing the return address, which it takes from the current value of PC, and jumping unconditionally to the subprogram. With such an instruction, our subprograms could be implemented like this:
h-1: 0
h: ...
jin h-1
...
f: ...
jsr h-1
...
...
g: ...
jsr h-1
...
The JSR instruction is not possible to implement with our current
architecture. The reason is simple: we need to store the current
value of PC in a cell in main memory. However, there is no data path
from PC to the data bus. In order to implement JSR, we need to add
such a data path.Here is a complete description of what JSR must do:
Notice the new MOPs number 21 and 22 to load the data register and to communicate its contents to the data bus respecitively. To implement JSR, we use the following plan:
......: 0010101010000000000000 (JSR) ......: 0000100000000000000010 (JSR) ......: 0000000001000000000001 (JSR) ......: 0001000001000000000001 (JSR) ......: 0011000001000000000001 (JSR) ......: 0001000001000000000001 (JSR) ......: 0000010001000000000000 (JSR) ......: 1000001000000000000000 (JSR)
A stack is a sequence of cells in memory one end of which is pointed to by a register called the stack pointer. That end is called the top of the stack. Four different but equivalent conventions are used according to whether the top of the stack is the highest or the lowest address in memory, and according to whether the stack pointer points to the top element of the stack or to the first free position beyond the top element. Here, we use the convention used by most Unix systems: the stack top is the lowest address and the stack pointer points to the top element.
Here are the modifications to our architecture in order to support a stack:
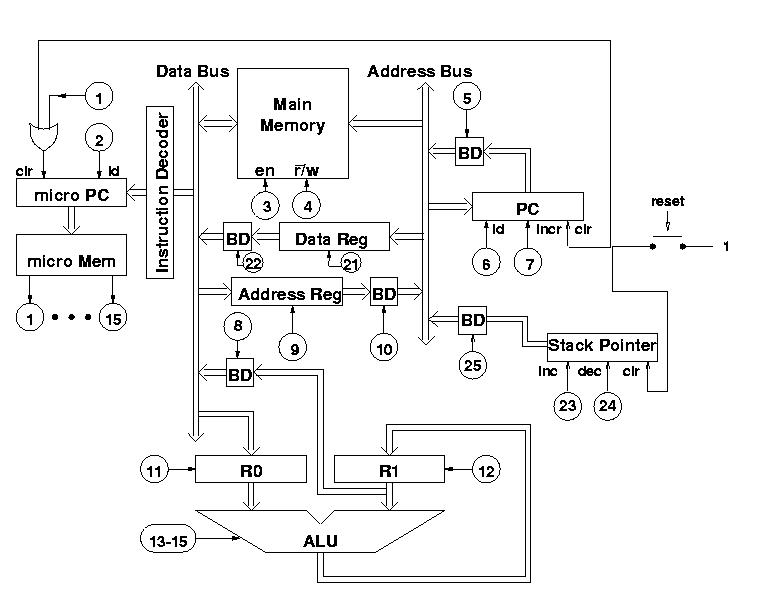
The stack pointer can be cleared, incremented and decremented. Clearing the stack pointer at reset time is justified, since one can view the memory as circular. Address 0 in memory can be seen as lying just beyond the end of the memory. Three new MOPs are needed, 23 for incrementation, 24 for decrementation, and 25 for communicating the contents of the stack pointer to the address bus.
With this new architecture we can redefine the JSR instruction and add a new instruction RET (for return). Here are our subprograms with these new instructions:
h: ...
ret
...
f: ...
jsr h
...
...
g: ...
jsr h
...
Here is the new description of the modified JSR instruction:
......: 0010101010000000000000000 (JSR) ......: 0000100000000000000010010 (JSR) ......: 0000000000000000000001001 (JSR) ......: 0001000000000000000001001 (JSR) ......: 0011000000000000000001001 (JSR) ......: 0001000000000000000001001 (JSR) ......: 1000010001000000000000000 (JSR)Here is the plan for implementing the RET instruction:
......: 0010000010000000000000001 (RET) ......: 1000010001000000000000100 (RET)